
Turning the Plastic Problem into a Machine Learning Challenge
Written by Dhivya Sreedhar, 2025 Machine Learning and Computer Vision Intern
Every year, more than 350 million tons of plastic are produced worldwide — and most of it doesn’t get recycled. One of the biggest hurdles? Sorting. Different plastics have different properties, and to recycle them effectively, they need to be separated by resin type, shape, and color.
At Reclamation Factory, we asked a simple question:
Could we teach a machine to see what a human sorter sees — and do it faster, more accurately, and at scale?
Why Sorting Plastics Is Hard
On the surface, it sounds straightforward: point a camera at a plastic object, classify it, and sort it into the right bin.
In reality, it’s much more complex:
Visual similarities: Two bottles may look identical but be made from completely different resins.
Real-world variability: Lighting conditions, backgrounds, and wear-and-tear change how plastics appear.
Limited public datasets: While there are many open datasets for everyday objects, very few exist for plastic resin identification.
We realized we’d need to build our own dataset from scratch — and that’s where the real work began.
Building the Dataset from Scratch

Image labeling interface and pipeline.
Instead of relying on internet images, we collected thousands of real-world samples:
Sources: Plastics from production lines, recycling centers, and consumer packaging.
Diversity: Captured under varied lighting, angles, and backgrounds to mimic real-life sorting environments.
Labeling: Each image was carefully annotated with its resin type (e.g., PET, HDPE, PP), shape (bottle, container, film), and color.
We also balanced the dataset so no class dominated — essential for fair model training.
Since our mission is practical recycling, we focused on categories that show up frequently in real-world waste streams but are otherwise difficult to recycle in municipal MRFs:
PET Clear Clamshells (with and without stickers)
PP Tubs
Pill Bottles
Data Augmentation: Teaching Robustness
Sorting facilities aren’t controlled labs — plastics appear under different lighting, with dirt, scratches, and even damage.
To prepare the model for these conditions, we used heavy on-the-fly augmentation:
Geometric: random rotations, flips, zooms.
Photometric: brightness/contrast shifts, Gaussian noise, blur.
Contextual: varied backgrounds to mimic conveyor belts and bins.
Augmentation effectively doubled the training dataset size and boosted test accuracy by ~7%, especially in the challenging “Other” class. Each class had about 600 images, giving us a balanced dataset of ~3,600 samples. Balancing was key — we didn’t want the model to overfit to one dominant class while neglecting the rest.
Data Augmentation: Teaching Robustness
We explored several approaches before landing on an efficient design suitable for deployment:
Baseline Transfer Learning
Models like ResNet-50 and MobileNetV2, pretrained on ImageNet, gave us a strong starting point.
We swapped their final layers with classification heads tailored to our dataset.
Custom Multi-Head Model
A shared backbone learns general plastic features.
Three separate output heads predict resin, shape, and color simultaneously.
This structure allowed the model to learn both shared representations and specialized outputs.
Training Setup
Optimizer: Adam with learning rate scheduling.
Loss: Categorical Cross-Entropy, weighted to address class imbalance.
Regularization: Dropout layers and early stopping to prevent overfitting.
This design gave us both accuracy and deployability for real-world conveyor belt systems.
How Well Did the Model Perform?
Once trained, we evaluated the model on a held-out test set.
The heatmap below shows strong diagonal performance, with occasional confusion between visually similar plastics (e.g., clamshells with vs. without stickers):
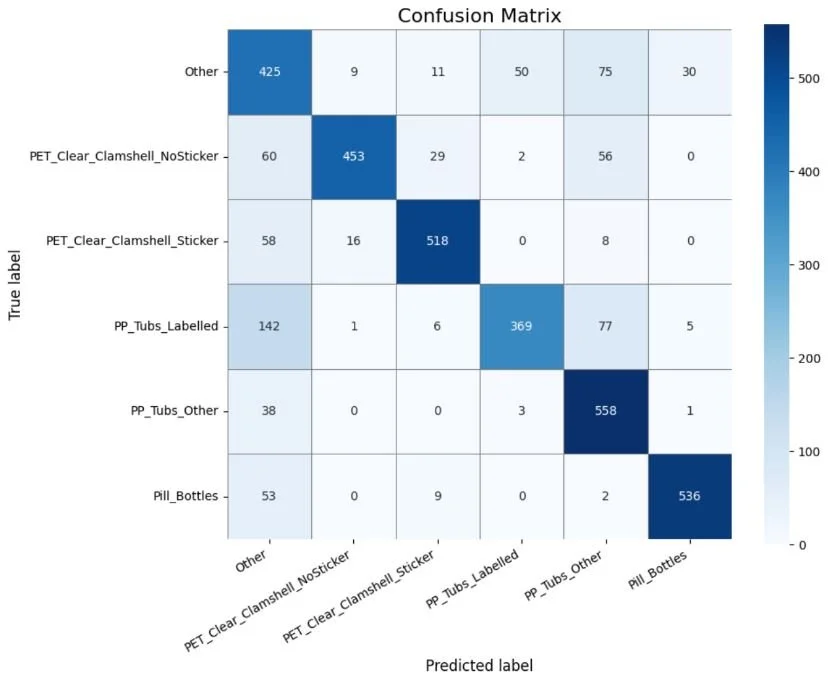
Confusion matrix showing a strong correspondence between predicted and actual plastic waste labels.
PET Clear Clamshells (with/without stickers): Precision and recall over 90%, showing the model learned subtle sticker cues.
Pill Bottles: F1-score of 0.91, despite color/shape variability.
PP Tubs (Other): Recall as high as 0.93, making it one of the best-performing classes.
“Other” category: Lower F1-score (0.61), reflecting the difficulty of grouping diverse plastics together.
Overall accuracy: ~79% (macro F1: 0.79) — a strong baseline considering real-world variability.
From Lab to Conveyor Belt
These results aren’t just academic. When integrated into recycling infrastructure, this system can:
Reduce sorting errors by up to 30%.
Save hundreds of tons of plastic from downcycling or landfill.
Enable higher-quality recycled resin, lowering costs for manufacturers.
This bridges the gap between AI and environmental impact.
Plastics are one of today’s toughest environmental challenges — but with machine learning, we can make recycling smarter, faster, and more effective. Because the cleaner we sort today, the more sustainable tomorrow becomes.